
Motivation
The following body of text has no technical content whatsoever, feel free to jump to the technical overview.
As far as I know we are all apes going through the World trying to understand it and ourselves. The better way to understand one-self is to keep track of the things that matter (to us), is all about tracking from a place of curiosity. I would like to keep track of certain core Habits that (by my own definition) would signal whether I am living a “good life”, independent of my occupation, where I live, or the people around me. A good life is defined by what we do in our days, then, what we do every day is of absolute importance. My Habits of choice are somewhat cliche, hard to achieve consistently but completely under my control (most of the time):
- Wake up before 6am.
- Do some sort of physical activity (every day), a measure that I have not been completely sedentary during the day.
- At least 5 hours of productive/deep work or any activity with a degree of responsibility.
- Eat clean (No sugar, No refined carbs).
In a nutshell, my inner ape tells himself that if by the end of the day those 4 key Habits are done, not matter what (weather, mood, breakup, etc), that was a great day. Have enough “great days” and by the compounding effect, all of a sudden you will be living a great life.
Problem
The bullet journal is my weapon of choice for Habit tracking. Sadly, apart from the visual component, the analog choice leaves very little room for analysis over time. Also, 3 out of 4 habits are already being tracked automatically from my daily usage of certain services (fitbit, toggl, etc); Given that my data from these services is readily available from their public API’s, the process of tracking my habits is ripe for automation. Moreover, by having my data segregated over different services I will be giving up on the benefits of: correlations, averages and trends, not to mention that I will not own the data, not really, unless I control the database.
Inspired by Exist, this project was born for all the above-mentioned reasons, thus it is not a toy project and I hope to grow it over time as a personal life-companion tool. The application is currently live on https://ape.danicos.me for the grafana dashboard (temporal front-end) and on https://ape.danicos.me/v1/ for the API.

Technical overview
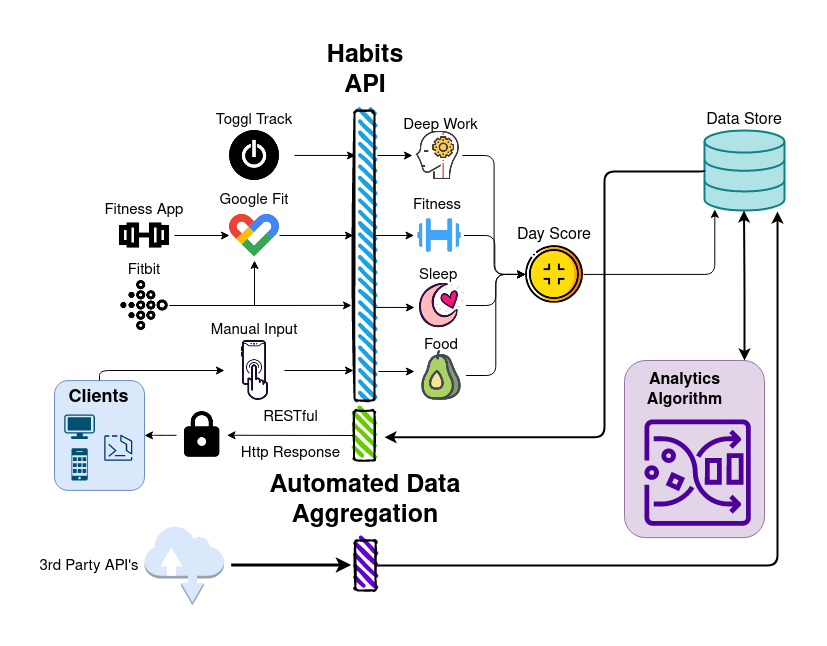
The Curious Ape project is mainly a Self-data aggregation tool whose MVP is centered around automated habit tracking. At its heart the application is intended to be an automated data harvesting tool which will gather all possible data of the user that is scattered across its many services around the web. Down the road, the application is meant to have a personalized dashboard (frontend) to bring all of the user’s data into one easy to visualize place, as well as an aggregator service (algorithm) that will analyze and correlate all data points in order to generate insights about the user’s behaviour.
Currently, only data collection related to the 4 core Habits is implemented. Once deployed, the Habits API is scheduled to pull my self-data at the end of the day from 3rd party API’s. Once in the system the data is mapped to my own data models of deep work (tasks, projects, dates), fitness (duration, start/end, exercises, progresive overload, steps) and Sleep (duration, quality, wake-up time); The schemas live in the project’s migration files. Food habits are tracked manually via a cli client:
Once the data is mapped to the Curious Ape models, some checks run to establish the actuality (or not) of the Habits. With the habits already checked, a score between 0 and 4 is given to the day given the presence of the habits, 0 will be no habits where done that day and 4 will be all habits where done. The Habits API effectively applies a map/reduce automated operation on the data coming from the 3rd party API’s.
Scores:
- 0 = abysmal day
- 1 = bad day
- 2 = mediocre day
- 3 = good day
- 4 = great day
Habits API
The backend concerns itself mainly with automated data collection (inputs), however there is a thin RESTful API layer that exists to respond with my (normalized) data collected from all over the internet, as well as data derived from the analytics algorithm (coming soon).
Clients
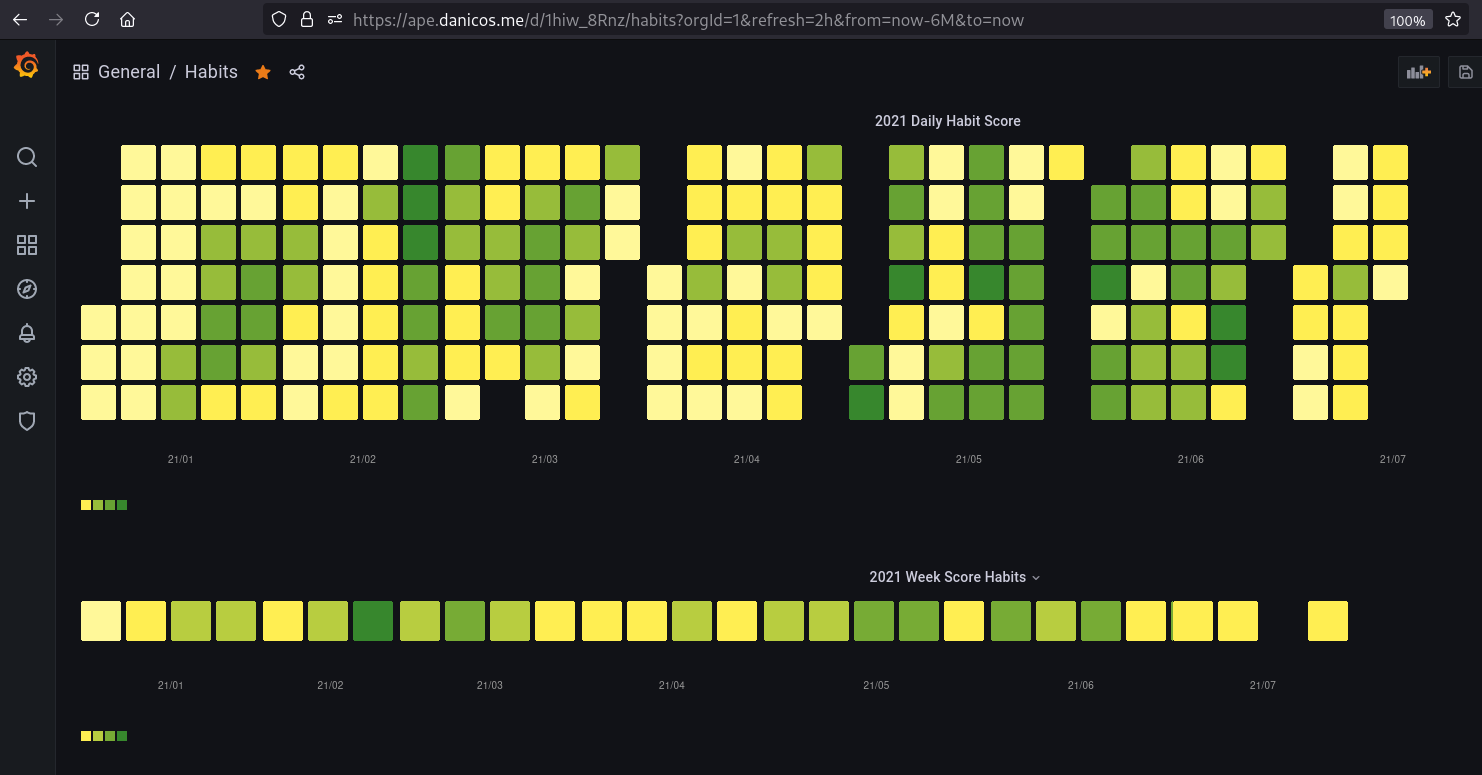
A proper Web client is on the works for data visualization purposes. For now I have a lightweight Cli client written in Golang and a Grafana dashboard to visualize my habits in a calendar-based heatmap.
Tech Stack
- Programming language: Golang 1.19
- Persistence: Sqlite
- Production: Digital Ocean, Droplet (Ubuntu VPS)
- Api testing: Postman
- Source control: Git
- Dashboard: Grafana
- Reverse Proxy: Caddy
- API Gateway and TLS Termination Caddy
- Continuous deployment strategy: Makefile
- Immutable deployment strategy: Shell Script
- Schema Migration strategy: Migrate
- Development environment: Linux
- Editor: Jetbrains: Goland
- Shell: Fish
Roadmap
-
CI strategy
- Unit tests to prevent regression
- Integration tests
- End to end tests
-
Automated data collection for all my services
Some popular services with public API’s:
- Google API’s (Google health, timeline/maps, email, youtube, calendar)
- Goodreads (Books)
- Waka Time (Programming)
- Rescue Time (Productivity)
- Github (Programming)
- My Fitness pal, Fitbit, Strava (Health & Fitness)
- Facebook, Twitter, Instagram (social)
- Swarm (Location)
- Toggl (Productivity)
- Etc…
-
Analytics algorithm
- Correlations
- Averages
- Trends
-
Proper clients
- Web
- Mobile
- More robust CLI